A Deep Dive into Kubernetes Pod Lifecycle
Table of Contents
- Understanding Kubernetes Pod Lifecycle
- Phase 1: Pending
- Phase 2: Running
- Phase 3: Succeeded
- Phase 4: Failed
- Phase 5: Unknown
- Visual Representation
- Additional Information and Sources
Understanding Kubernetes Pod Lifecycle
Kubernetes Pods go through several phases between their creation and deletion. Each phase represents a broader lifecycle state of the Pod and provides insights into what’s happening under the hood. Knowing these phases in detail helps DevOps engineers and SREs efficiently troubleshoot and optimize deployments.
Phase 1: Pending
Definition: A Pod is in the Pending phase when it has been accepted by the Kubernetes API server, but one or more of its containers has not yet been scheduled onto a Node.
Example Scenario: You create a new deployment with resource limits that are too high (resources.requests.memory: 64Gi), and your cluster doesn’t have enough capacity. The pod remains in Pending as it can’t be scheduled anywhere.
Pod Creation Failures
An invalid manifest may prevent the Pod from even being created.
Fix:
- Run
kubectl apply --dry-run=client -f pod.yaml - Use tools like
kubeval,kubectl explain, orkube-linter
Scheduling Failures
Examples:
nodeSelector: disktype: ssdbut no nodes match- Pod requesting 2 CPUs, but nodes only have 1 available
Fix:
- Ensure labels are accurate and nodes match selection
- Scale up or optimize resource usage
Phase 2: Running
Definition: A Pod enters the Running phase once it has been scheduled to a node, and all containers have been created. At least one container is still running or is starting.
Example Scenario: You deploy a web application that uses an init container to copy static assets, followed by a main app container that starts the web server. If the init container runs successfully and the app starts, the pod will remain in Running.
Init Container Failures
Failures here delay app startup.
Example:
- Init container tries to access a secret volume that doesn’t exist.
Fix:
- Check logs:
kubectl logs <pod> -c <init-container>
Application Container Startup Issues
Examples:
- Misspelled image tag causes
ImagePullBackOff - App crashes due to missing environment variable (
CrashLoopBackOff) - Liveness probe set to port 8080, but app listens on 3000
Fix:
- Adjust image references, container command, and probe configs
Phase 3: Succeeded
Definition: A Pod is in the Succeeded phase when all containers in the Pod have terminated successfully (i.e., exited with status code 0) and will not be restarted.
Example Scenario: You run a Kubernetes Job to back up a database. Once the backup completes and the container exits normally, the Pod status becomes Succeeded.
No remediation is needed unless the termination was unintentional (e.g., incorrect loop condition that led to early exit).
Phase 4: Failed
Definition: A Pod is in the Failed phase when all containers in the Pod have terminated, and at least one container terminated with a non-zero exit code or was terminated by the system.
Example Scenario:
- A container tries to run a script that fails due to a
missing fileerror - Memory-intensive workload exceeds the defined memory limit (
OOMKilled)
Fix:
- Use
kubectl logs <pod>to inspect failures - Adjust memory limits and optimize code behavior
Phase 5: Unknown
Definition: A Pod is in the Unknown phase when the state of the Pod cannot be obtained, usually due to a communication error between the node and the control plane.
Example Scenario: A node crashes or becomes unreachable due to network issues. The kubelet on that node can’t report the pod status, so Kubernetes marks the pod as Unknown.
Fix:
- Run
kubectl get nodesto check node health - Use cloud provider metrics or logs to debug node connectivity
- Evict or reschedule affected pods if necessary
Visual Representation
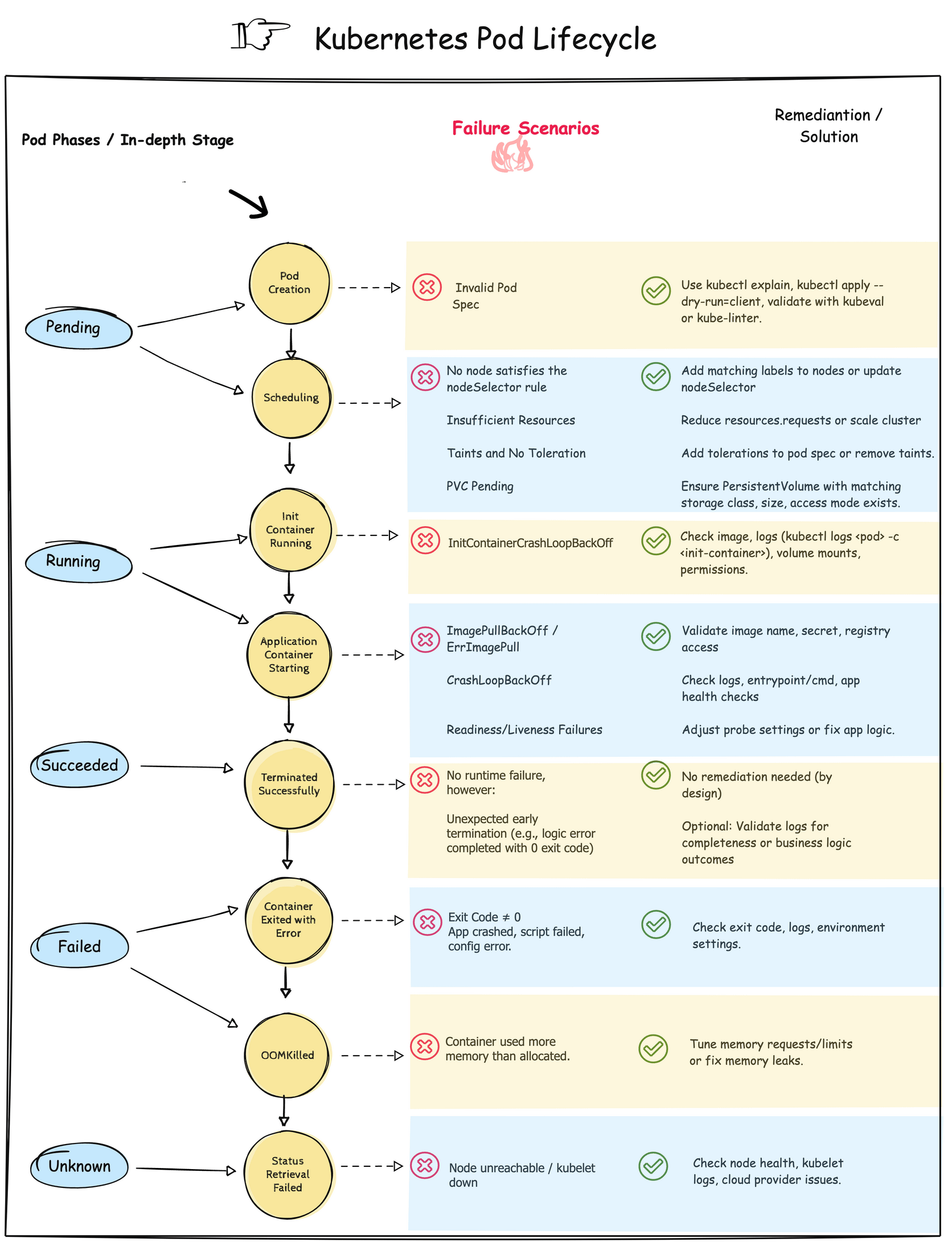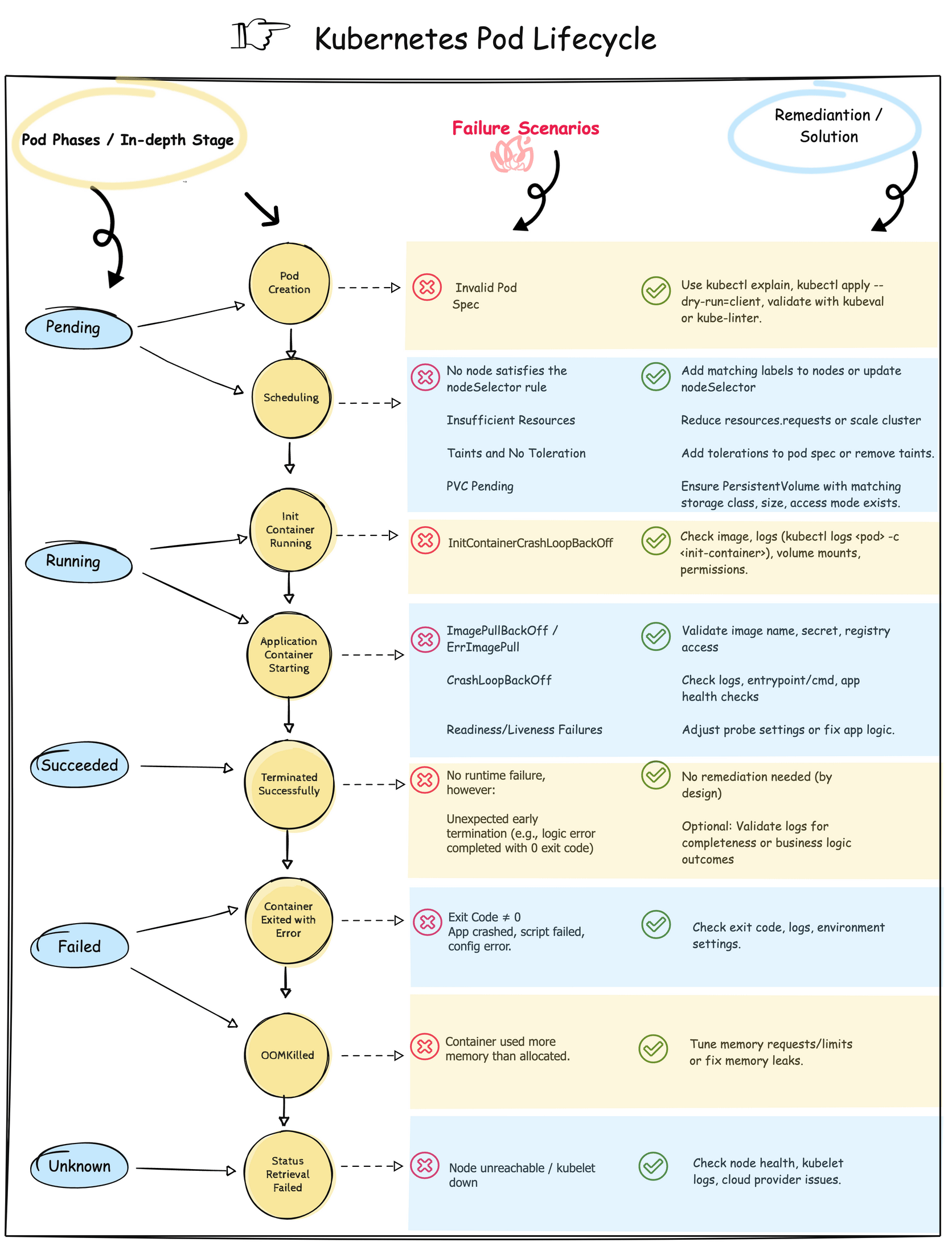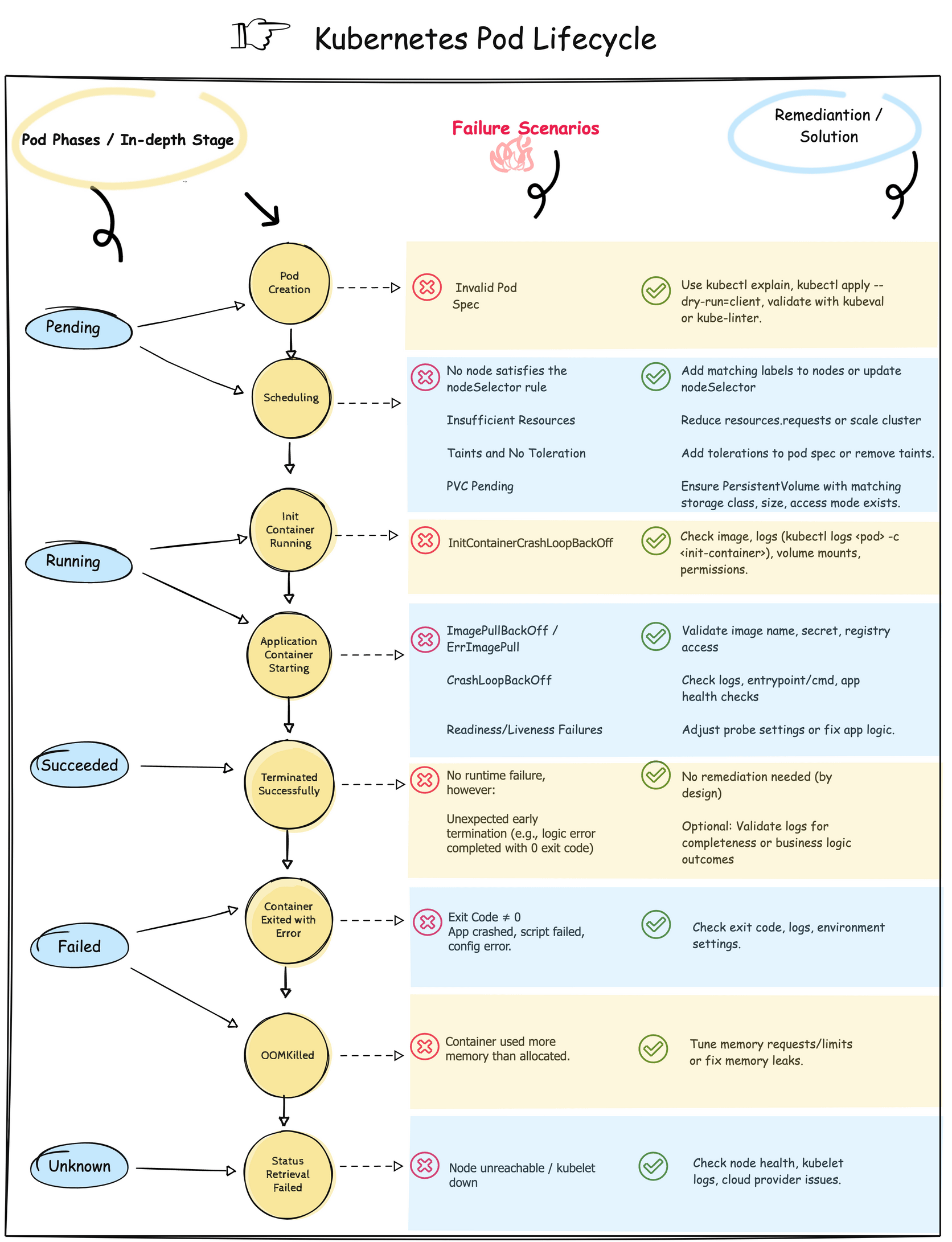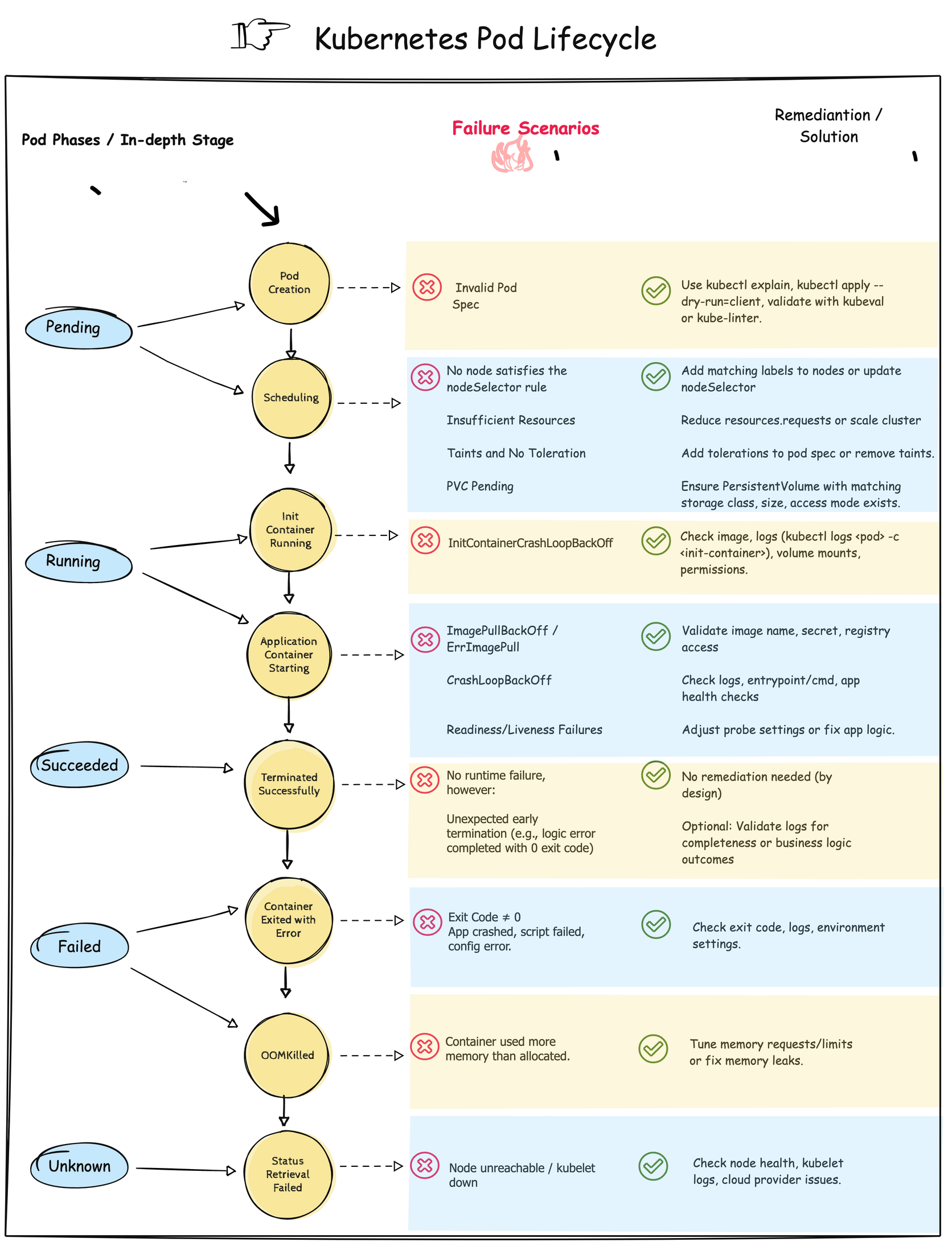
This visual outlines the five main pod phases along with detailed failure points and suggested solutions.
Additional Information and Sources
To deepen your understanding of Kubernetes Pod lifecycle and related troubleshooting, consider exploring the following resources:
- Kubernetes Official Documentation – Pod Lifecycle
- Kubernetes Troubleshooting Guide
- Kubelet Documentation
- Kubernetes Probes (Liveness, Readiness, Startup)
- kubectl Cheat Sheet
- Tools for Manifest Validation:
If you’re running Kubernetes on a managed service like GKE, AKS, or EKS, refer to their respective docs for platform-specific behaviors around scheduling, taints, and node health checks.